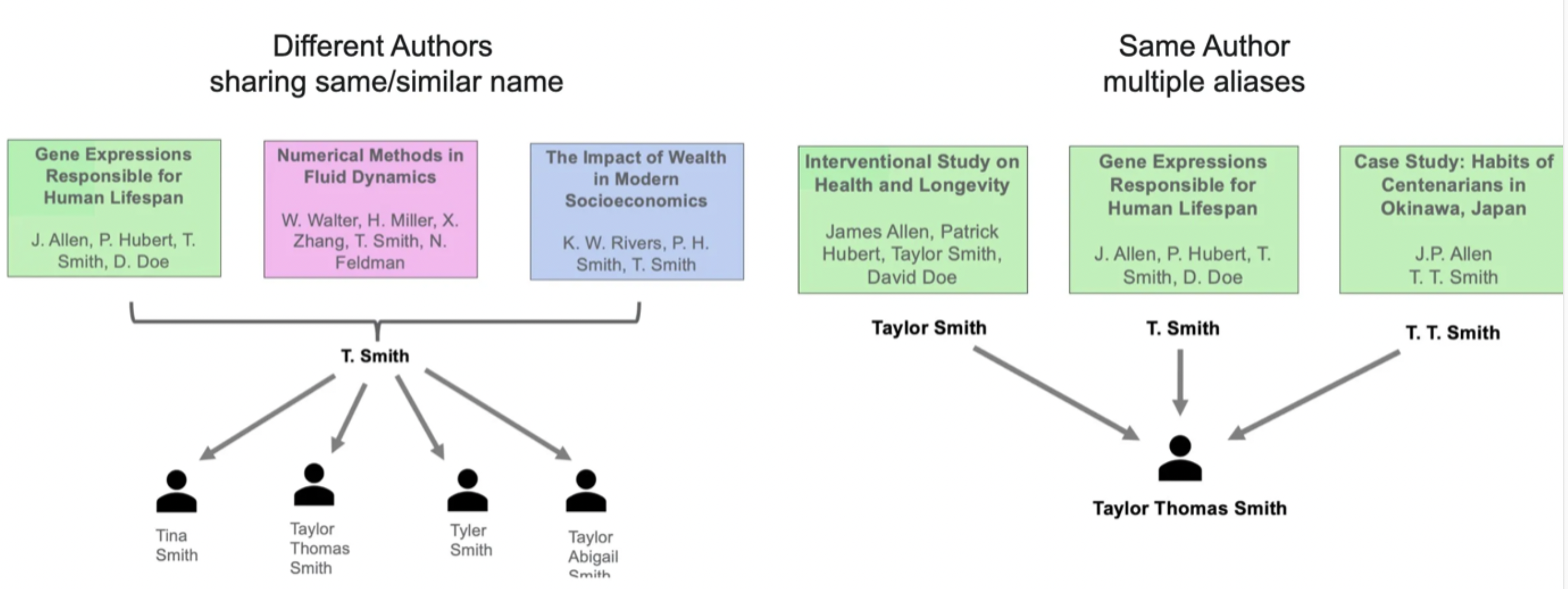
S2AND Inference on Custom Data
Introduction In this post, we actually run the saved model we have on file on the our own custom dataset. The Code S2AND comes with a production model that has already been pretrained on their own collection of data. To run the production model on your unique datasets, simply run the code below: import pickle # reload model with open("data/production_model.pkl", "rb") as _pkl_file: clusterer = pickle.load(_pkl_file) dataset_name = 'fake' #this points to folder with generated data DATA_DIR = os....